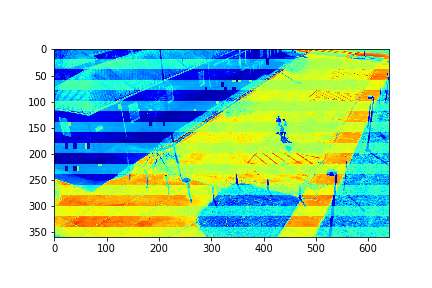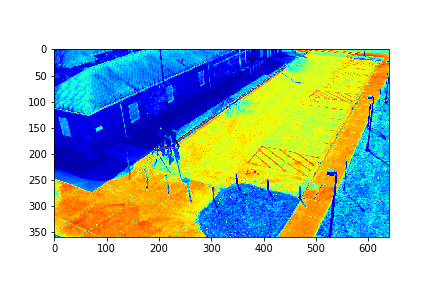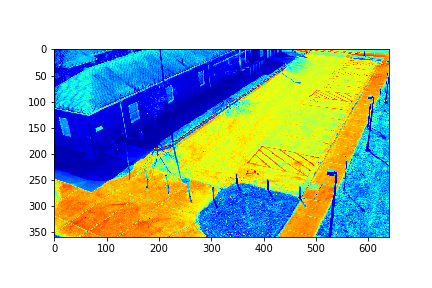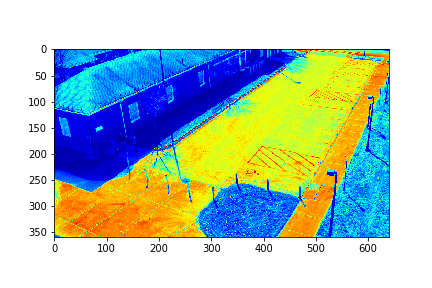
Set 0 Full Video
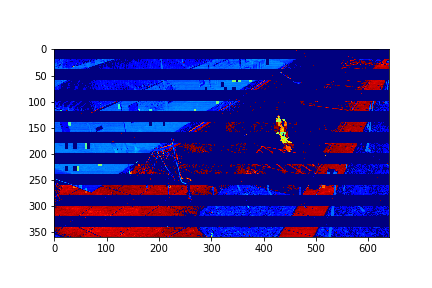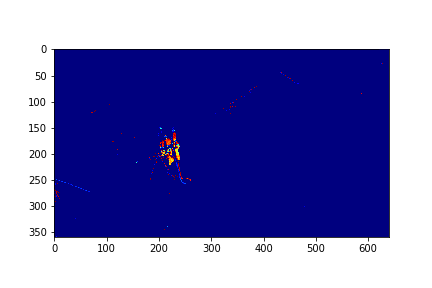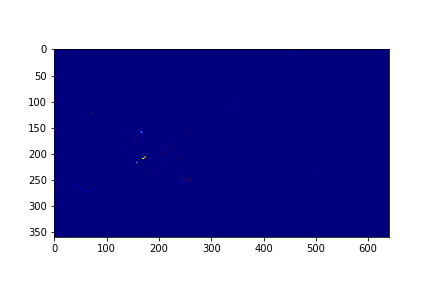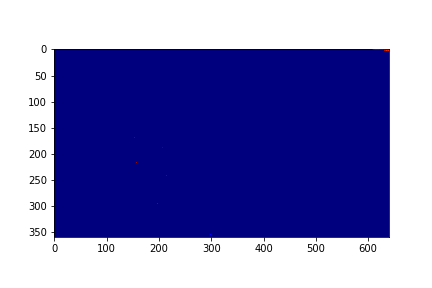
Set 0 Foreground Video
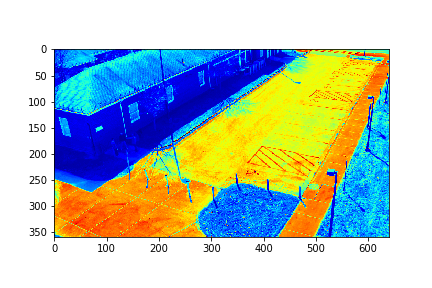
Set 0 Background
The background for this set is the set's 151th mode in this case.
This project in Dynamic Mode Decomposition is focused on the application of a relatively new time series decomposition method called Dynamic Mode Decomposition (DMD), for the purpose of foreground-background separation in surveillance video. The primary goal is to replicate the procedure discussed in the following research paper by J. Grosek and J. Nathan Kutz [1], but on a different surveillance video.
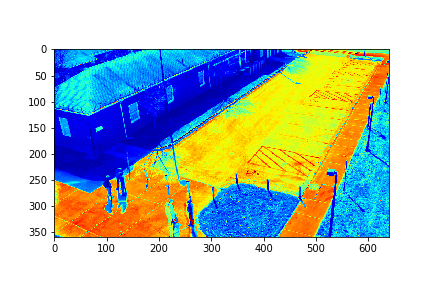
The surveillance video was taken from the VIRAT Release 1 Sample Database [2], and is survellance of some sort of exchange happening in a parking lot. DMD was used to have the video eparated into a set of modes, which are kind of like a set of videos that can each be represented by a mathematical function.In the latest iteration of this project, the surveillance video was first downgraded to a grey color scheme and was then reduced in resolution by a factor of 3 in both width and height. Then only every tenth picture extracted from the video was considered. The considered pictures were split into a sequence of four sets, labeled 0,1,2,3. Then each of these sets, which contained 200 pictures, were run through the DMD algorithm. For each set run through DMD, 198 modes were returned.
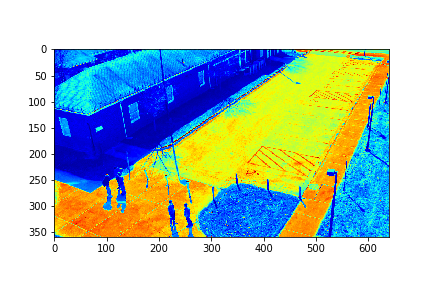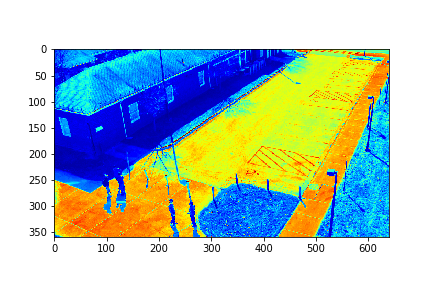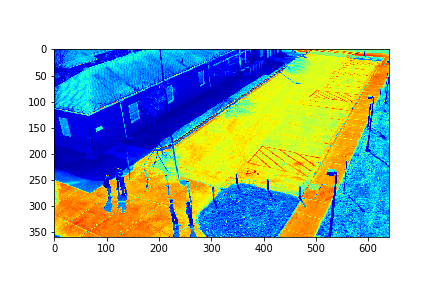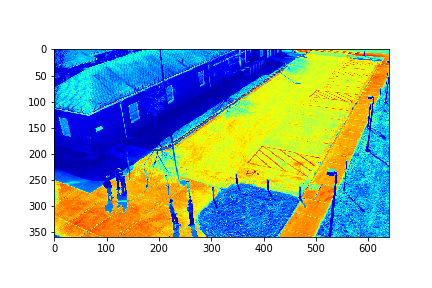
For each set, the mode/video that involves the least change (is closest to a stand-still picture), is considered to be the background mode. The foreground mode is the sum of all of the remaining modes. This is also the same as subtracting the background mode from the original video for its set. Below are the three types of considered videos for each of the four sets: Full,foreground, and background.
The background for this set is the set's 151th mode in this case.
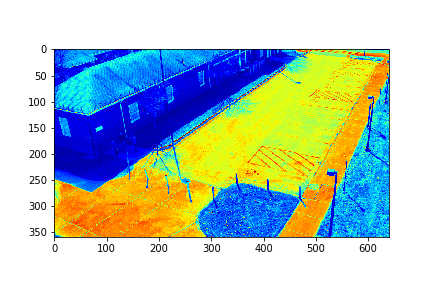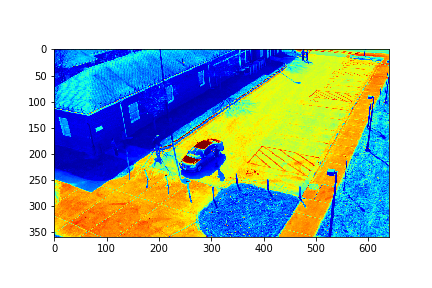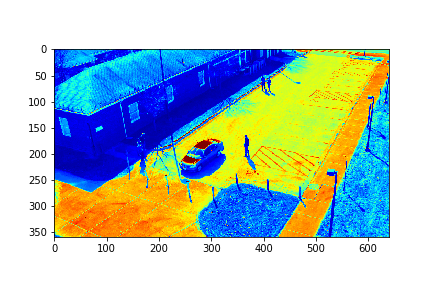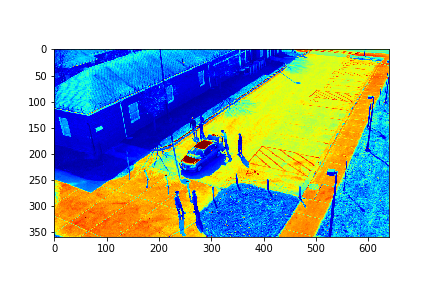
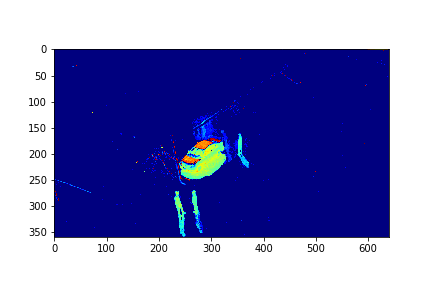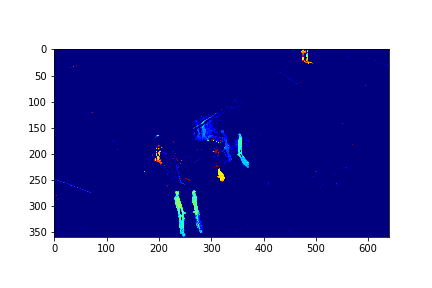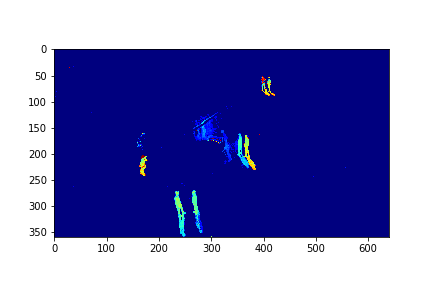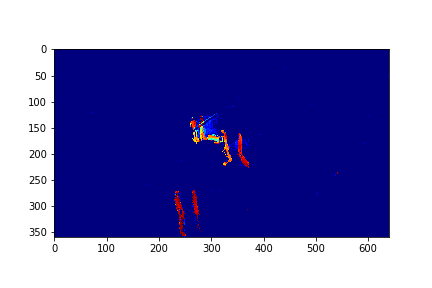
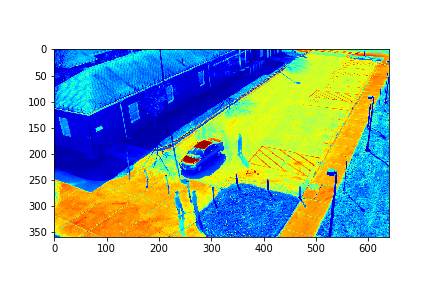
The background in this case is the 183rd mode of this set.
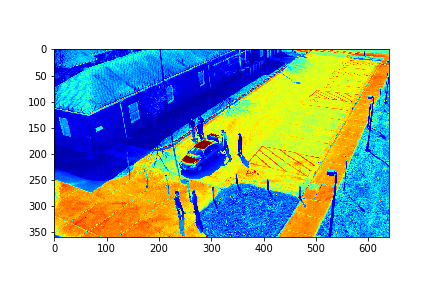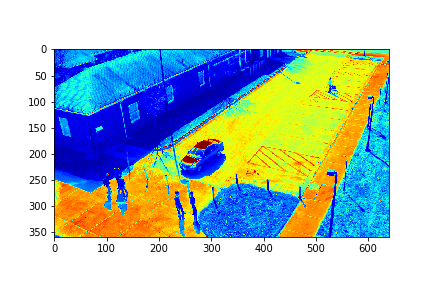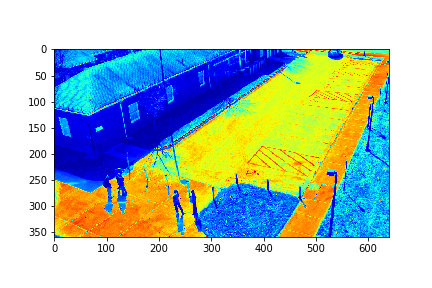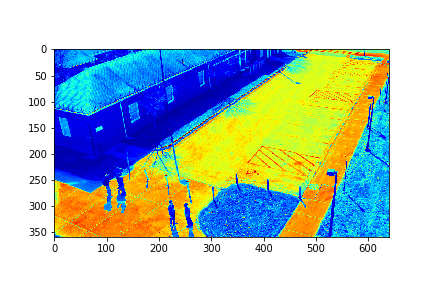
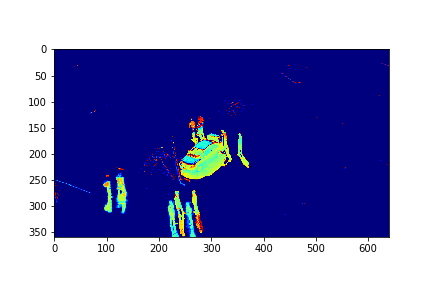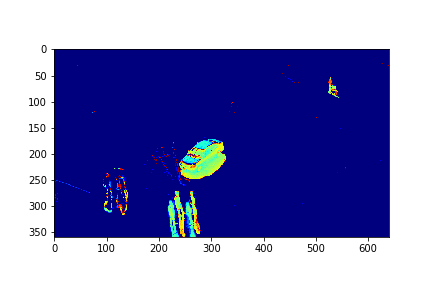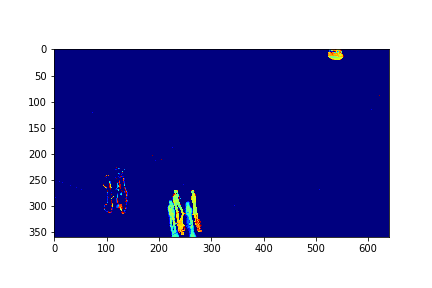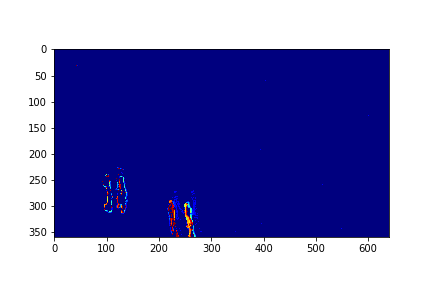
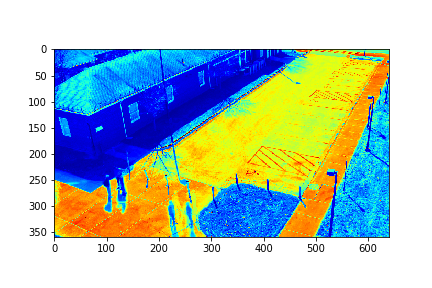
The background for this set is its 73rd mode.
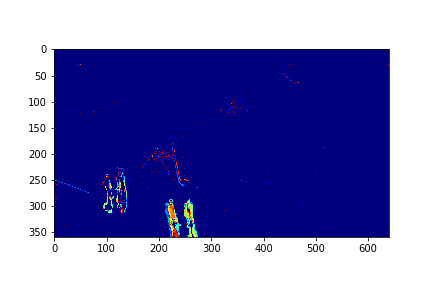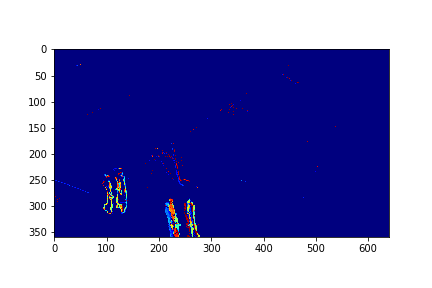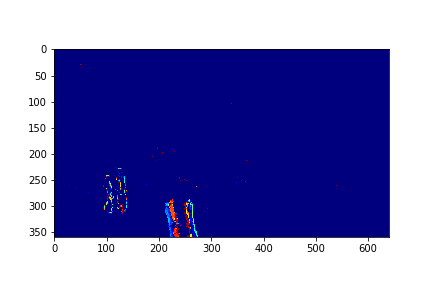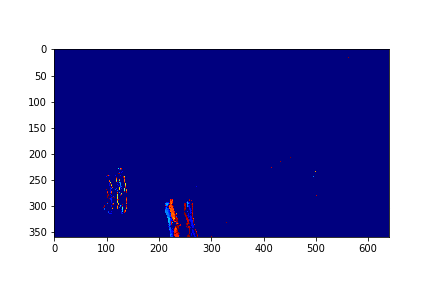
The set 3 Background is the 155th set of set 3.
[1] J. Grosek and J. N. Kutz Dynamic Mode Decomposition for Real-Time Back- ground/Foreground Separation in Video. arXiv: 1404.7592vl [cs.SV] 30 Apr 2014
[2] The video to be considered for the analysis is from the VIRAT Release 1 Sample Database. To quote the VIRAT website https://viratdata.org/, VIRAT is "A Large-scale Benchmark Dataset for Event Recognition in Surveillance Video" by Sangmin Oh, Anthony Hoogs, Amitha Perera, Naresh Cuntoor, Chia-Chih Chen, Jong Taek Lee, Saurajit Mukherjee, J.K. Aggarwal, Hyungtae Lee, Larry Davis, Eran Swears, Xiaoyang Wang, Qiang Ji, Kishore Reddy, Mubarak Shah, Carl Vondrick, Hamed Pirsiavash, Deva Ramanan, Jenny Yuen, Antonio Torralba, Bi Song, Anesco Fong, Amit Roy-Chowdhury, and Mita Desai, in Proceedings of IEEE Comptuer Vision and Pattern Recognition (CVPR), 2011."
Click to see Revised Project Report (as of January 6th.)